K-Means Clustering을 통한 선수 스카우팅
재미로 보는 축구 데이터 , 여섯 번째는 K-Means Clustering을 통한 선수 스카우팅입니다.
K-Means Clustering 알고리즘은 대표적인 비지도 군집화 알고리즘으로 비슷한 요소들을 묶어 레이블을 달아주는 알고리즘입니다.
k-평균 알고리즘 - 위키백과, 우리 모두의 백과사전 (wikipedia.org)
k-평균 알고리즘 - 위키백과, 우리 모두의 백과사전
k-평균 알고리즘(K-means clustering algorithm)은 주어진 데이터를 k개의 클러스터로 묶는 알고리즘으로, 각 클러스터와 거리 차이의 분산을 최소화하는 방식으로 동작한다. 이 알고리즘은 자율 학습의
ko.wikipedia.org
다양한 축구 리그의 선수 데이터를 수집하고 이를 통해 축구 선수들을 군집화 하여 축구 선수 스카우팅에 사용해보도록 하겠습니다.
필요한 정보는 다양한 축구 리그에 속해있는 선수들의 데이터입니다.
데이터는 웹 크롤링을 통해서 수집하였으며 , 다양한 축구 선수들 데이터가 존재하는 Whoscored.com에서 수집하였습니다.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from pandas.io.html import read_html
import time
import pandas as pd
import numpy as np
url = "https://1xbet.whoscored.com/Regions/252/Tournaments/2/Seasons/7811/Stages/17590/PlayerStatistics/England-Premier-League-2019-2020"
defensivePath = '//*[@id="statistics-table-defensive"]'
offensivePath = '//*[@id="statistics-table-offensive"]'
passingPath = '//*[@id="statistics-table-passing"]'
defensiveName = "Defensive"
offensiveName = "Offensive"
passingName = "Passing"
sleepTime = 2
defensiveDF = ['Player', 'Player.1', 'Apps', 'Mins', 'Tackles', 'Inter', 'Fouls', 'Offsides', 'Clear', 'Drb', 'Blocks', 'OwnG', 'Rating']
offensiveDF = ['Player', 'Player.1', 'Apps', 'Mins', 'Goals', 'Assists', 'SpG', 'KeyP', 'Drb', 'Fouled', 'Off', 'Disp', 'UnsTch', 'Rating']
passingDF = ['Player', 'Player.1', 'Apps', 'Mins','Assists','KeyP','AvgP','PS%','Crosses','LongB','ThrB', 'Rating']
#browser = Service(".\chromedriver.exe")
driver = webdriver.Chrome(executable_path='chromedriver')
driver.get(url)
def getEnsive(name, columsTable, xmlPath):
time.sleep(sleepTime)
defense = driver.find_element_by_link_text(name)
defense.click()
time.sleep(sleepTime)
all_player = driver.find_element_by_link_text('All players')
all_player.click()
time.sleep(sleepTime)
page = driver.find_element_by_link_text('last')
total_page = int(page.get_attribute('data-page'))
df_defensive = pd.DataFrame(columns = columsTable)
for i in np.arange(total_page)+1 :
time.sleep(sleepTime)
table = driver.find_element_by_xpath(xmlPath)
table_html= table.get_attribute('innerHTML')
df2 = read_html(table_html)[0]
df_defensive = pd.concat([df_defensive, df2], axis=0)
driver.find_element_by_link_text('next').click()
return df_defensive
df1 = getEnsive(defensiveName, defensiveDF, defensivePath)
df2 = getEnsive(offensiveName, offensiveDF, offensivePath)
df3 = getEnsive(passingName, passingDF, passingPath)
df = pd.concat([df1, df2, df3], axis = 1)
df = df.T.drop_duplicates().T
df3
print(df3)
df.reset_index(drop=True, inplace=True)
def toCsv(tableName, path,check):
tableName = tableName.reset_index()
tableName.drop(['index','Player'] , axis=1, inplace=True)
spl = tableName['Player.1'].str.split(',')
name = []
for i in range(len(spl)):
a = spl[i][0]
name.append(a)
tableName['name']= name
age = []
for i in range(len(spl)):
a = int(spl[i][1])
age.append(a)
tableName['age'] = age
position1 = []
for i in range(len(spl)):
a = spl[i][2]
position1.append(a)
tableName['position1']=position1
position2 = []
for i in range(len(spl)):
if len(spl[i]) > 3 :
a = spl[i][3]
else :
a = np.nan
position2.append(a)
tableName['position2'] = position2
tableName.drop('Player.1', axis =1, inplace=True)
if check == 0:
tableName = tableName.iloc[:,[11,12,13,14,0,1,2,3,4,5,6,7,8,9,10]]
tableName.to_csv(path, sep=',', encoding='utf_8_sig')
else:
tableName = tableName.iloc[:, [10,11, 12, 13, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9]]
tableName.to_csv(path, sep=',', encoding='utf_8_sig')
defensiveCsv = toCsv(df1, "./defensive.csv",0)
offensiveCsv = toCsv(df2, "./offensive.csv",0)
passingCsv = toCsv(df3, "./passing.csv",1)
위 코드를 통해서 Whoscored.com에 존재하는 리그의 2년 치 선수 데이터를 수집하였습니다.

수집된 데이터는 유럽 5대 리그와 포르투갈 , 벨기에 , 네덜란드 등등 수집할 수 있는 최대한의 데이터를 수집하였고 , 시즌의 경우 가장 최근의 완료된 2개의 시즌에 대하여 수집하였습니다.
수집된 선수의 데이터에 대한 설명입니다.
| 데이터 Feature | 설명 |
| Season | 선수가 경기를 뛴 해당 시즌 (ex 2020 – 2021) |
| League | 선수가 속한 리그 |
| Name | 선수의 이름, 이번 데이터에는 소속팀까지 포함 |
| Age | 선수의 나이 |
| Position1 | 선수의 주 포지션 |
| Position2 | 선수의 부 포지션 |
| Apps | 선수가 한시즌에 뛴 선발 경기수 , 괄호 안은 교체 출전 |
| Mins | 선수가 한시즌에 뛴 경기 분수 (ex 900 => 900분) |
| Tackles | 경기당 평균 태클 수 |
| Inter | 경기당 평균 인터셉트(공을 빼앗은) 횟수 |
| Fouls | 경기당 경고 횟수 |
| Offsides | 경기당 오프사이드 승리 횟수 (수비) |
| Clear | 경기당 공을 걷어낸 횟수 |
| Drb(수비) | 경기당 드리블을 통과 시킨 횟수 (수비) |
| Blocks | 경기당 상대 선수를 막은 횟수 |
| OwnG | 기록한 자책골 수 |
| Goals | 전체 골 기록 수 |
| Assists | 전체 도움 기록 수 |
| SpG | 경기당 슈팅 횟수 |
| KeyP | 경기당 키 패스 (주요한 패스) 횟수 |
| Drb(공격) | 경기당 드리블 횟수 |
| Fouled | 경기당 파울당한 횟수 |
| Off | 경기당 오프사이드 횟수 |
| Disp | 경기당 공 소유권을 잃은 횟수 |
| UnsTch | 경기당 좋지 않은 볼 컨트롤 횟수 |
| AvgP | 경기당 패스 횟수 |
| PS% | 패스 성공률 (퍼센테이지 %) |
| Crosses | 경기당 크로스 횟수 |
| LongB | 경기당 롱볼 횟수 |
| ThrB | 경기당 던지기 횟수 |
| Rating | 선수의 평균 평점 |
데이터를 분석하고 사용하기 이전에 , 방향을 잡기 위해 대략적인 데이터의 분포를 살펴보도록 하겠습니다.
전체를 다 살펴보기에는 양이 많으니 Tackle , Inter , Blocks , Goals , Assists에 대해서 살펴보도록 하겠습니다.


Box Plot을 통해 살펴본 데이터의 대략적인 분포입니다.
박스를 넘어선 점들이 다수 분포하는 것으로 보아 Outlier들이 다수 분포하고 있음을 알 수 있습니다.
해당 Outlier 들은 해당 데이터 Feature에서 압도적이고 뛰어난 성적을 보여주는 선수 일 것입니다.
데이터를 전처리하는 과정에 있어 Outlier를 제거하거나 가공하고 데이터를 분석하지만 , 해당 Outlier의 경우 뛰어난 선수들에 대한 데이터 이므로 제거하지 않고 분석하도록 하겠습니다.
이번에는 경기 수가 적은 , 경기를 얼마 뛰지 못한 선수에 대해서 살펴보겠습니다.
경기 수가 적을수록 해당 선수가 보여준 퍼포먼스에 대한 신뢰도는 떨어지게 됩니다.
1경기만을 치르고 좋은 성적 혹은 나쁜 성적을 받은 선수와 30경기 동안 꾸준히 좋은 성적 혹은 나쁜 성적을 받은 선수를 유사하다고 판단하기는 어렵습니다.
따라서 치른 경기수가 많을수록 보여준 퍼포먼스에 대한 신뢰도는 높아질 것이고 , 이는 분석에 사용할 데이터의 신뢰성을 의미합니다.
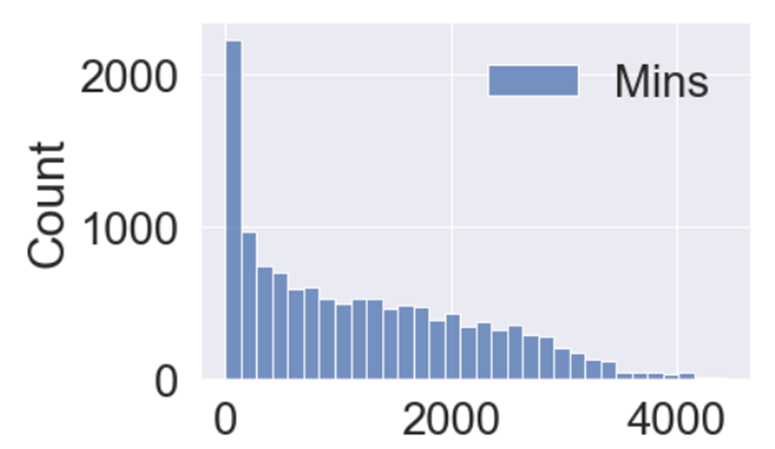
따라서 데이터를 전처리하는 과정에서 특정 경기수 이하인 선수들을 모두 제거하고 살펴보도록 하겠습니다.
이 선수들을 제거하지 않고 살펴보는 것도 물론 의미가 있지만 , 축구선수 스카우팅이라는 관점에서 살펴보는 만큼 좀 더 의미 있는 결과를 낼 수 있도록 전처리하였습니다.
또한 전처리하는 과정에서 잘못 수집된 Null 데이터들을 삭제하고 , 각 Feature들에 대해 StandardScaler를 적용하였습니다.
비지도 학습이라고 하더라도 모델에 대한 Test 결과를 확인할 필요가 있으므로 , 데이터를 Train set , Test set으로 나누어 진행하도록 하겠습니다.
따라서 진행할 축구선수 K-Means Clustering에서는 K = 50 , 100 , 150 , 200 , 250 , 300의 경우에 전체 Feature를 사용하고 한 시즌에 900분 미만 (평균적으로 10경기 미만) 으로 뛴 선수들을 제거하고 진행하겠습니다.

각 경우에 대하여 K-Means Clustering을 진행하였고 , 기준 선수를 입력하면 해당 기준 선수와 어떤 선수들이 함께 군집화 되었는지 살펴보도록 하겠습니다.
첫 번째로는 뛰어난 선수와 같은 군집에 속한 유명하지 않은 선수를 찾아보도록 하겠습니다.
먼저 Rating Feature에 대한 Interquartile range를 확인하여 Outlier를 찾아냅니다.

등장한 뛰어난 선수들 중 돈얄 말렌 (PSV , 19-20) 선수와 유사한 선수를 찾아보도록 하겠습니다.


K-Means Clustering의 K가 50 ~ 300인 경우에 대해서 확인하였고 , 각 K 경우에 대하여 클러스터에 속한 선수 수는 다음과 같습니다.
K = 50 : 100명 / 100 : 50명 / 150 : 26명 / 200 : 29명 / 250 : 22명 / 300 : 14명
K가 점점 커지면서 점점 세밀한 Clustering이 진행되므로 , 대부분의 클러스터들 안에 속한 선수수는 줄어들 것입니다.
모든 경우를 확인하기는 어려우므로 K = 200 인 경우에 대하여 한 선수만 대표적으로 비교해보도록 하겠습니다.


위의 경우 돈얄 말렌 선수가 속한 112번 그룹에 대한 Test 데이터와 Train 데이터입니다.
Test 데이터들 중 한 선수와 돈얄 말렌 선수의 데이터를 비교해보고 어느 정도 일치하는지 확인해보도록 하겠습니다.
비교할 선수는 20-21 벨기에 리그의 Beerschot에서 뛴 Tarik Tissoudali (타릭 티수달리) 선수입니다.

비교해본 결과 어느 정도 비슷한 퍼포먼스를 보여주었던 것을 확인할 수 있습니다.
만약 눈으로 보이는 것처럼 돈얄 말렌 선수 같은 뛰어난 선수급의 퍼포먼스를 보여주었다면 , 타릭 티수달리 선수의 몸값에도 변화가 있을 것입니다.

확인해본 결과 , 티수달리 선수의 몸값이 20 - 21 시즌 크게 상승한 것을 확인할 수 있었습니다.
또한 늘 자유계약으로 이적하던 티수달리 선수는 이번 시즌 좋은 활약을 보여주고 벨기에 명문팀 KAA 헨트로 이적한 것을 확인할 수 있습니다.
티수달리 선수의 이적 , 몸값 상승 , 보여준 데이터를 통해 확인한 결과 뛰어난 선수급의 활약을 보여준 선수라고 볼 수 있을 것 같습니다.
이번에는 살펴볼 기준 선수를 뛰어난 선수가 아닌 일반적인 주전급 선수로 두고 살펴보도록 하겠습니다.

EPL 브라이튼의 닐 무페이 선수를 통해서 한번 살펴보겠습니다.
닐 무페이 선수는 Test set에 속한 선수로 이번 경우는 수집된 모든 데이터에 대해 모델이 만들어져 있고 , 완성된 모델에 살펴보고 싶은 기준 선수를 입력하는 경우로 살펴보겠습니다.


각 K = 50 ~ 300 인 경우에 대해 닐 무페이 선수와 같은 군집에 속한 선수수는 다음과 같습니다.
K = 50 : 151명 / 100 : 76명 / 150 : 63명 / 200 : 34명 / 250 : 26명 / 300 : 30명

K = 300인 경우 닐 무페이 선수는 191번 클러스터에 속해있고 , 이때 같은 리그의 사우스햄튼에서 뛰는 체 아담스 선수도 함께 191번 클러스터에 속하였습니다.
체 아담스 선수와 닐 무페이 선수를 비교해보도록 하겠습니다.

닐 무페이 선수와 체 아담스 선수도 어느 정도 유사한 퍼포먼스를 보여주는 것을 확인할 수 있습니다.
이번에도 좀 더 정확히 알아보기 위해 몸값을 확인해보도록 하겠습니다.

체 아담스 선수와 닐 무페이 선수 모두 해당 시즌이 끝날 때의 몸값이 20M 유로인 것을 확인할 수 있습니다.
즉 같은 리그 안에서 비슷한 성적을 보여주니 비슷한 몸값을 기록했다고 생각해볼 수 있습니다.
몸값과 퍼포먼스 데이터를 함께 확인한 결과 체 아담스 선수도 닐 무페이 선수와 비슷하다고 볼 수 있을 것 같습니다.
비지도 학습인 만큼 결과에 대한 정확도를 측정하기 어렵습니다.
따라서 이번 분석에 대한 결과 역시 의견이 나뉘고 해석이 다를 수 있다고 생각합니다.
또한 선수의 몸값 데이터를 활용하거나 , 중요 데이터 Feature에 가중치를 두거나 , 모델에 사용할 데이터 Feature를 선택하는 것으로 더 좋은 결과나 Insight를 얻을 수 있다고 생각됩니다.
기회가 된다면 다른 글에서 또 살펴보도록 하겠습니다.
정리
- K-Means Clustering 알고리즘을 통해서 축구 선수를 군집화 하였고 이를 축구 선수 스카우팅 관점으로 살펴보았다.
- 실제로 퍼포먼스 데이터와 선수 몸값을 비교하고 살펴본 결과 , 어느 정도 유사한 선수들끼리 군집화 된 것을 확인할 수 있다.
- 선수의 몸값 데이터나 각 리그의 순위를 활용하면 좀 더 의미 있는 결과를 얻을 수 있을 듯하다.
'데이터 분석 > 축구 데이터 분석' 카테고리의 다른 글
| 8. 유럽 5대 리그의 일등 , 꼴등팀에게 전 라운드 베팅 - [1] (0) | 2022.05.19 |
|---|---|
| 7. EPL 20/21 경기 배당률과 발생한 점수 관계 (0) | 2022.01.16 |
| 5. EPL 03/04 ~ 20/21 시즌 사이 가능한 등수 변화 (0) | 2021.10.11 |
| 4. EPL 20/21 시즌 최근 5경기 전적으로 살펴본 다음경기 결과 (0) | 2021.08.30 |
| 3. EPL 20/21 시즌 의적팀 알아보기 (0) | 2021.08.22 |



